The field of economics began with theory (Adam Smith and The Wealth of Nations), later adding data and statistics. By the 1940s, people began exploring human behavior with simple games, which led to the important field of game theory. As computers became more widespread they began to be applied to economics. At UC Berkeley in the early 1960s, Frederick Balderston and Austin Hoggatt wrote an elaborate discrete event simulation of the lumber industry. As timesharing advanced, they envisaged computerizing the business simulation experiments up until then being run with written rules, paper forms, etc.
In the 1960s Hoggat and Balderston established the Management Science Laboratory at Berkeley’s Center for Research in Management Science: a 2800 square feet (260 square meters) space with reconfigurable partitions, teletypes, and closed-circuit video cameras and monitors. A combined PDP-5/PDP-8 minicomputer system ran the experimenter’s application system and logged timestamped responses. One of first experiments was a duopoly situation designed to see whether collaboration would take place even though the subjects were in isolated cubicles, interacting only via simulated market interactions.
By 1970, Hoggatt was ready to upgrade the computer system. APL had arrived in 1968 and Hoggatt felt it would combine experiment programming, data analysis, and publication. But APL wasn’t available on a sufficiently powerful, inexpensive computer at that time. Instead of asking NSF for a bigger computer, he proposed spending the money on building a one-off hardware/microcode/software system that could provide general timesharing as well as efficient APL processing.
The money was granted; between 1972 and 1976 the hardware was acquired and/or built, the microcode and software written, and experiments run. The system ran a few more years but was shut down because of high maintenance costs. Nevertheless it helped establish the field of computer-based behavioral research. Today software packages like z-Tree from Universität Zürich allow easy setup using networks of laptops.
“History of CRMS APL” [IEEE; unlocked] (Paul McJones, IEEE Annals, 2026 Jan-Mar) tells the story of CRMS and its APL upgrade from my point of view—as a person who wrote the APL microcode in 1972 and then left the project, only to take up research for this paper in 2024. The paper is based both on project materials I collected plus materials from the Bancroft Library at Berkeley. The materials I collected are available here: crms-apl.computerhistory.org.
The References section of Peter Naur’s paper “The European Side of the Last /Phase of the Development of ALGOL 60” in the first HOPL conference [1] includes an item that begins:
ALGOL 60 documents (1959–1960). Unpublished technical memoranda prepared in connection with the ALGOL 60 conference in Paris, 1960, Jan. 11–16. During the conference the available documents were numbered 1 to 30. Here the numbers 31 and 201 to 221 have been used for further related documents.
and continues with a long numbered sequence of items. I’ve long wished I could see the actual items. Recently I learned that Naur’s son Thorkil donated Naur’s papers to the Niels Bohr Institute and scanned and curated all the ALGOL 60 papers (plus some related ALGOL 58 items) and posted them online at the Dansk Datahistorisk Forenings (Danish Data History Association):
The papers and notes by Naur and others during his involvement with Algol 60 during 1959 and 1960 (plus a 1970 letter to Donald Knuth serving as a key to many of the documents). Most of the actual papers are in English.
Peter Naur. Hvorledes Algol 60 blev til (Danish: How Algol 60 was created). Colloquium at the Datalogisk Institut, 10 March 1972. Transcript. Audio.
L-R: Michael Levin, Lowell Hawkinson, Ed Fredkin. 16 August 2016. Courtesy of Mark David.
Michael I. Levin died on 14 August 2025. He played important roles in the original LISP 1.5 project and the follow-on LISP 2 project. Later he cofounded Gensym, which developed a real-time expert system. He had a lifelong interest in teaching, perhaps influenced by his parents, who were both school teachers. This account was pieced together from my email connections with him between 2005 and 2017, my research on the LISP 1.5 and LISP 2 projects, a 2019 interview by his cousin Alan Kadin, and a 2009 resume. It only covers Levin’s professional career, although an important part of his life was following the teaching of Chögyam Trungpa.
Levin was born in Paterson, New Jersey and grew up in nearby Totowa. He did well in school and applied to five colleges, choosing M.I.T. and enrolling in fall 1958. He majored in mathematics but was attracted to computer science, taking a graduate course by Marvin Minsky in his sophomore year. Minsky proposed a problem—providing an effective definition of “Random Sequence”—that engaged Levin and apparently provided a topic for his undergraduate thesis. He also coauthored a technical report with Minsky and Roland Silver entitled “On the effective definition of ‘Random sequence'” (AI Memo 36 revised; undated).
Apparently even before he graduated (in 1962), Levin had joined McCarthy’s Lisp project. His first publication was “Arithmetic in LISP 1.5” (AI Memo 24, April 1961), which noted it was an excerpt from the upcoming LISP 1.5 Programmer’s Manual. A version of that manual was released on July 14, 1961; its preface notes “This manual was written by Michael Levin starting from the LISP I Programmer’s Manual by Phyllis Fox.” But the final August 17, 1962 version simply states “This manual was written by Michael I. Levin.” There was another significant change between the two versions: the former said “The compiler was written by Robert Brayton with the assistance of David Park” while the latter said “The compiler and assembler were written by Timothy P. Hart and Michael I. Levin. An earlier compiler was written by Robert Brayton.” Apparently Brayton’s compiler, which was written in assembly language, was more difficult to maintain than the Hart-Levin compiler, which was written in Lisp (see “The New Compiler”, AI Memo 39) and could compile itself (after being “bootstrapped” using the interpreter). In 2013, he mentioned to me that one of his contributions to the compiler was converting a class of tail-recursive calls to iteration, a transformation that became much more well known in the 1970s. See this recent explanation of how Levin’s PROGITER function worked.
In 1962 McCarthy left M.I.T. but continued his work at Bolt Beranek & Newman (BBN); Levin joined him there. In 1963 McCarthy moved to Stanford to found an AI Laboratory. Levin may have briefly worked with McCarthy there, but by 1963 he was at M.I.T. working on a system for proof checking, as evidenced by his report “Primitive Recursion” (AI Memo 55, July 1963). Also he and his colleague Tim Hart wrote “LISP Exercises” (AI Memo 64, January 1964), intended to be used with the first chapter of The LISP 1.5 Programmer’s Manual. Perhaps they were teaching a course? Later in 1964, as the hardware for M.I.T.’s Multics operating system was being designed, Levin wrote: “Proposed Instructions on the GE 635 for List Processing and Push Down Stacks” (AI Memo 72, September 1964). Tom Van Vleck, creator of Multicians.org, told me:
I was at a big meeting where the 645 was presented to many users of the Project MAC facilities, mostly CTSS at the time. Corby led the presentation and multiple others covered various aspects. Ted Glaser talked about the associative memory and paging.
Many folks had questions. Mike raised the issues in his memo. … Ted Glaser responded, and Mike responded to that, and it was clear that the issue had many details that would have to be resolved. Mike kept asking for commitments that the presenters weren’t ready to talk about. Finally, Ted said, “We can’t do it that way, it would overload the busses.”
It was possible that Ted was making this up to end the discussion… but Ted was incredibly smart, and thought faster than anybody, and who was going to argue with a blind genius?
In any event Levin’s LISP instructions were not added to the 645.
Around this time discussions at M.I.T. and Stanford began on a follow-on language, eventually named LISP 2. Looking back in 1978, McCarthy noted:
As a programming language LISP had many limitations. Some of the most evident in the early 1960s were ultra-slow numerical computation, inability to represent objects by blocks of registers and garbage collect the blocks, and lack of a good system for input-output of symbolic expressions in conventional notations. All these problems and others were to be fixed in LISP 2.
The project expanded beyond what either of the AI labs could take on and moved to the Systems Development Corporation (SDC) in Santa Monica, California. SDC was experienced at software development, but not at Lisp, so Information International, Inc. (III) was brought in as a subcontractor. III, founded by Ed Fredkin, employed a number of experienced M.I.T. Lisp programmers, including Levin and Lowell Hawkinson.
One defining feature of LISP 2 was a syntax based on Algol 60, designed by Levin: “Syntax of the New Language” (AI Memo 68, May 1964). But by 2012, he told me:
An important idea for LISP II, which I emphasized from the beginning, but which was never implemented, and was eventually shown not to be needed, was the source language translator. This had its roots as a pedagogical device used by John McCarthy to show that there is a formal analogy between LISP and Gödel numbering. It was important to Gödel’s proof of the incompleteness of arithmetic to show that a language of logical theorems and proofs could be mapped into the domain of non-negative integers. McCarthy wanted to emphasize that LISP had the same theoretical foundation as Gödel’s proof, only with the difference that the mapping was easy and intuitive rather than being humanly intractable.
Although Levin changed his mind about the importance, I think it had an impact through the paper “The LISP 2 Programming Language and System,” (FJCC 1966) planting the idea of Algol-like languages with dynamic data structures.
Levin was also thinking about the runtime requirements for the new language at this time: “New Language Storage Conventions” (AI Memo 69, May 1964). Around this time, it appears he moved to Santa Monica to work more closely with the SDC team, and wrote a series of technical reports probably best studied in context at this web site dedicated to the project.
Levin returned to M.I.T. in 1965, apparently as an instructor, thinking about mathematical logic: “Topics in Model Theory” (AI Memo 78, May 1965; revised as AI Memo 92, January 1966). His resume notes: “Developed and taught graduate course entitled Mathematical Logic for Computer Scientists“. The resultant book was published as an M.I.T. LCS report (TR 131, June 1974). The book caught the eye of famous logician Stephen Cole Kleene, who noted in a footnote of a 1978 paper:
It was pointed out to me in Oslo on June 13, 1977 by David MacQueen that computer scientists have developed the theory of working with the expressions of a given formal language as a generalized arithmetic to the extent that it is not necessary to reduce the language to the simple arithmetic of the natural numbers by a Gödel numbering or indexing. Cf. Levin 1974, Scott 1976. (An early example of generalized arithmetic is in IM § 50.)
(in the interview by Alan Kadin, Levin joked: “During my time at Stanford, I studied a book by Stephen Cole Kleene, Introduction to Metamathematics. As far as I know, I may be the only person who carefully read this entire book.)
In addition to BBN and III, Levin worked for Composition Technology, where he said he implemented the world’s first typesetting program.
In the early 1970s Levin went to Colorado, apparently attracted by the teaching of Chögyam Trungpa. He held several teaching and research positions there, and then in 1982 he became an associate professor of computer science at Acadia University in Nova Scotia.
Returning to Massachusetts in 1984, he joined LISP Machine, Inc. (LMI), one of the two companies that spun out of M.I.T.’s Lisp machine project. Levin designed the inference engine for PICON, LMI’s real-time expert system. By 1986 it became clear to him and several of his colleagues (including Lowell Hawkinson, with whom he’d worked at III) that LMI was failing, so they left and co-founded Gensym. Gensym’s G2 real-time expert system, similar to PICON but with a from-scratch implementation, was very successful for industrial process control. A 1996 initial public offering allowed Levin to finance his later retirement, although he also did consulting work from 1999 to 2004.
John McCarthy had a vision of a programming language for symbolic processing in artificial intelligence. Michael Levin was a central member of the team that turned that vision into a practical implementation. Throughout his career he combined effective engineering with mathematical insights.
This essay benefited from comments by Mark David, Roger Frye, and Alan Kadin. I’m also indebted to Alan for his oral history.
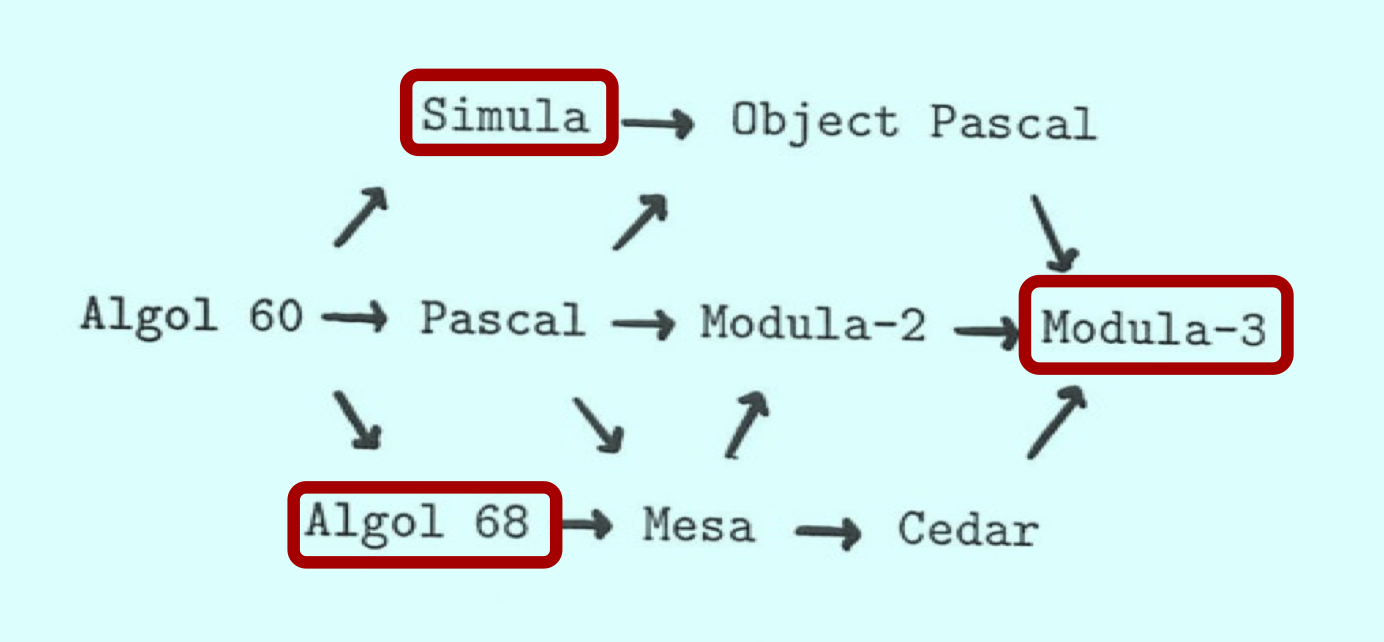
The diagram above, drawn by Nelson, gives an idea of its heritage. Mesa, designed at Xerox PARC in the mid 1970s, borrowed many ideas from Pascal, but added modules (with interfaces called DEFINITIONS modules and a module configuration language), exceptions, and threads (called processes, but they shared a single address space). Wirth spent a sabbatical at PARC, and decided to add definition modules to Modula-2. Meanwhile, PARC’s Cedar project extended Mesa with storage safety (via garbage collection) and runtime type determination. Then a core of PARC researchers followed their director Bob Taylor to establish the System Research Center (SRC) at DEC. They couldn’t take Cedar with them (it was proprietary, and ran only on exotic Dorado workstations). Another DEC lab had implemented a Modula-2 compiler, which the SRC people extended with their favorite Cedar Mesa features (exceptions, threads, garbage collection, and runtime type determination), naming the result Modula-2+. The nearby Olivetti Research Center, with other former PARC researchers, adopted this new language too. Seeing the utility of this language, Maurice Wilkes, retired from Cambridge but consulting at DEC and Olivetti, suggested to Wirth that Modula-2+ be revised and standardized as Modula-3. Wirth approved and the committee got to work, ultimately adding two important features, object types and generics; even still, the Modula-3 Report came in at just over 50 pages.
The SRC implementation at first generated C. Later the compiler was restructured with an interface making it fairly easy to substitute different code generators; one that used the back-end of gcc allowed widespread portability. Modula-3 adoption began spreading, facilitated by ftp to distribute source code and email and the comp.lang.modula3 newsgroup to share ideas and experience.
Researchers at SRC switched fairly quickly from Modula-2+ to Modula-3: the former was tied to older hardware, whereas Modula-3’s portability allowed it to run on the latest DEC ALPHA workstations. Projects included window system toolkits, algorithm animation, distributed systems, experimental programming languages, two-view and constraint-based editors, new web browsing paradigms, and program verification. Many of these projects produced libraries that became building blocks for subsequent projects. Researchers at several universities also found it a good base for ambitious projects, including an extensible operating system and an augmented reality system. One small company attempted to commercialize the language. An open-source developer used it to create the system used for many years to distribute FreeBSD source code.
Then Java came along, offering similar features plus “write once, run anywhere”—that plus Sun Microsystem’s marketing effort quickly eclipsed Modula-3. Even at SRC, researchers switched from Modula-3 to Java.
SRC’s system had always been open source, and there were several forks, including the commercial company’s proprietary version (which was later open-sourced). Gradually the forks were merged into two alternative releases, CM3 and PM3, which are both hosted at https://github.com/modula3/. CM3 will run on most modern platforms. Documentation exists, but isn’t always easy to navigate.
My personal interest in Modula-3 began when I worked at SRC and helped develop some of the standard library interfaces and an application. I hope the language will be remembered—and used—for many years to come.
Would this be of any interest to the Software Preservation Group?
I immediately agreed: Emacs has a long and honorable history with many implementations, and Lars is a skilled and prolific retro-computerist. By August of this year as I worked to rejuvenate the Software Preservation web site, I noticed that the Emacs page listed the major implementations of Emacs, but did not actually link to the content, whereas Lars’s github repository is filled with source code for a wide variety of implementations and a README that gives detailed provenance. After consulting with Lars, I revised the Software Preservation project to create a presentation layer detailing all the information in his GitHub repository. You can trace the history from the original version written in TECO macros, the Lisp Machine versions, TVmacs in the Architecture Machine Group, Multics Emacs, Prime Emacs, Montgomery Emacs, Gosling Emacs, Zimmerman Emacs, GNU Emacs (and its derivatives), Epsilon, and MicroEMACS.
If you think others should be included, you’ll have to convince Lars.
Twenty-two years ago the Computer History Museum established an advisory committee (with staff, trustees, and volunteers) to explore issues of identifying, collecting, preserving, and presenting software. The Museum had just moved into its present quarters; the main Revolution exhibit was still far in the future. But the previous year, Grady Booch had gotten the ball rolling with a mass email entitled “Preserving classic software products” asking for people’s “top ten list of classic software products.” The replies to that email and the ensuing discussion made it clear that software collection and preservation were worth doing and needed to begin immediately, before more pioneers died and more source code was lost or destroyed.
Monthly meetings of the Software Collection Committee began in November 2003, covering a wide range of topics. Should collection be proactive or reactive? What priorities should guide proactive collecting? (Grady’s compiled top-ten lists provided initial input.) How should software be cataloged? How should it be presented? An initial workshop in October 2003 mostly asked questions, but a follow-up in May 2006 showed off work from CHM and from other organizations and individuals.
While many discussions raged for months, restless folks began “pilot projects” to collect materials from the original IBM 704 FORTRAN project, Doug Engelbart’s NLS/Augment project, and the APL programming language. A web site was set up to present the results of these pilot projects and the monthly meetings. An email list with an archive allowed people who couldn’t attend the meetings to participate in many discussions.
As time passed, interest in software preservation expanded. The Museum opened its Revolution! exhibit in 2011 followed by Make Software: Change the World! in 2017. Its Software History Center centralized and expanded the software-related curatorial staff. Source code releases became a regular occurrence. Work also went on outside the Museum. Software Heritage, founded by INRIA, maintains a replicated repository and populates it by crawling the world’s open-source software “forges” such as GitHub.com.
At the same time, the committee (renamed Software Preservation Group) lost mindshare: The meetings wound down in 2007, and traffic on the email list tapered down to a standstill by 2017. However, encouraged by the success of my original FORTRAN project, I had continued with a series of projects including LISP and C++. After retiring in 2010 I took on larger projects on ALGOL, Prolog, SETL, and BCPL and smaller ones on GEDANKEN, Mesa, PAL, and Poplar, plus program verification systems AFFIRM and PIVOT. Along the way, a few other people found their way to the Software Preservation Group, and created projects: Interactive C Environments (Wendell R. Pepperdine), Emacs (Lars Brinkhoff), and FOCAL (Bruce Ray).
By 2025, the “Projects” section of the Software Preservation Group web site was still serving a useful purpose, but the overall web site was showing its age: the landing page suggested activities no longer in progress, the underlying Plone content management system hadn’t been updated in 20 years created a burden on the Museum’s IT group to keep running and backed-up, and the use of a different domain deemphasized the connection to the Museum. Discussions with David Brock and Hansen Hsu of the Museum’s Software History Center led to the idea of rebuilding the web site with static HTML on a subdomain of the Museum’s regular computerhistory.org.
As the author of most of the content, I took on this effort in July 2025. It was fairly easy to convert the project web pages I’d created, but I wasn’t sure what to do with projects created by others that had seen little or no activity for years and decades. I managed to contact the original authors, and worked with them to tidy things up (especially Emacs). I also tracked down materials from the 2003 workshop, almost all the meetings (agendas, minutes, and presentation handouts), and the email archive.
While waiting for word back from the NLS/Augment and APL projects, I couldn’t resist starting a brand-new project: the Modula-3 programming language. That will be the subject of another post.
Reading the Summer 2025 issue of Berkeley Engineer magazine, I was sad to note this item:
Robert Brayton died in January at the age of 91. He was a professor emeritus of electrical engineering and computer sciences and a pioneer in logic synthesis and formal verification. His career spanned multiple decades, including 26 years at the IBM Thomas J. Watson Research Center, where he led the Yorktown silicon compiler team and helped create one of the most advanced logic synthesis systems of its time. There, he also co-developed the sparse tableau methodology, which remains a foundational technique in modern circuit simulation. Brayton later joined the faculty at UC Berkeley, where he co-authored numerous influential papers and books and helped develop multilevel logic synthesis, which is widely used in the design and verification of complex logic systems and is a core component of Electronic Design Automation (EDA).
Robert K. Brayton (1933-2025)
In addition to these impressive accomplishments, while earning his Ph.D. in Mathematics at M.I.T. Brayton worked in John McCarthy’s Artificial Intelligence project on the design and implementation of Lisp. The 1960 LISP I Programmer’s Manual by McCarthy et al. [1] says: “The compiler was written by Brayton with the assistance of [David] Park.” But by 1978, when he wrote his paper for the first History of Programming Languages Conference, McCarthy asserted that Brayton’s compiler was “unsuccessful”.
Kazimir Majorinc, while researching the early history of Lisp, contacted Brayton by email for his version of the story and presented it in his talk “Who wrote the first Lisp compiler?” [2] Brayton described McCarthy’s HOPL comment as “unfair” and said this slightly edited version of Fred Blair’s 1970 remark [3] is “much more accurate” [Brayton’s edits in brackets]:
The first Lisp compiler was written by Robert Brayton with the assistance of David Park, in SAP for the 704. That compiler was started in [1958] and was [fully] working in [1961] by which time Brayton left MIT. During that interval of time a Lisp compiler written in Lisp was implemented by Klim Maling but that compiler was apparently dropped. [I am not sure it ever worked fully.] The argument advanced was that Brayton’s, being written in assembly language, would obviously be faster. Difficulties in maintenance developed when Brayton left the project. After Brayton and Maling, Timothy Hart and Michael Levin wrote a compiler in Lisp which was distributed with the 704 Lisp 1.5 system.
Herbert Stoy’s bibliography [4] attributes two compiler-related documents to Brayton, and after he donated his Lisp collection [5] to the Computer History Museum in 2010 I was able to scan those documents, neither of which identifies the author or date. They seem to be describing a compiler written in Lisp, so presumably they were written by either Klim Maling or Hart and Levin. [6, 7]
McCarthy was clearly very interested in the compiler. One of his first memos about programming languages was “Proposal for a Compiler,” written in 1957 and sketching ideas for languages like Algol and Lisp (neither of which existed yet) on a foundation not unlike Fortran (just being released). [8] Later (probably 1959) he wrote a memo giving code sequences to be generated for various Lisp constructs. [9] In any case, it seems likely that Brayton’s remarks to Majorinc best capture what really happened.
References
[1] J. McCarthy, R. Brayton, D. Edwards, P. Fox, L. Hodes, D. Luckham, K. Maling, D. Park and S. Russell. LISP I Programmer’s Manual. Computation Center and Research Laboratory of Electronics, Massachusetts Institute of Technology, March 1, 1960. www.softwarepreservation.org
[2] Kazimir Majorinc. Who wrote the first Lisp compiler? Slides for talk at Hacklab Mama, Zagreb, November 17, 2012. PDF at kazimirmajorinc.com
[3] Fred W. Blair. Structure of the Lisp Compiler. IBM Research, Yorktown Heights, circa 1970. www.softwarepreservation.org
[8] J. McCarthy. Memo to P. M. Morse: A Proposal for a compiler. Memo CC-56, Computation Center, Massachusetts Institute of Technology, December 13, 1957, 19 pages. www.softwarepreservation.org
[9] J. McCarthy. Notes on the Compiler. Memo 7, Artificial Intelligence Project, RLE and MIT Computation Center. Undated, 2 pages. www.softwarepreservation.org
When I began researching the history of LISP in 2005 [1], one of the first people I got in touch with was John Allen. Not only had he helped create Stanford LISP 1.6, written an influential book on the LISP language and its implementation (Anatomy of LISP), but also he and his wife, Ruth Davis, had organized (and funded!) the 1980 LISP conference [2] and founded The LISP Company, which produced TLC Lisp for Intel 8080- and 8086-based microcomputers. By the time I got in touch with him he was busy preparing a talk for another LISP conference [3], but told me:
in 1964 i got interested in lisp and wrote to mit. tim hart responded, sending the distribution tape and wished my luck. i needed it because the mit tape was for a machine related, but not identical, to the one i had at work. so to make a long story short, i got the tape converted and running.
what i have is a november 1964 listing of the tape’s contents. that includes the source card-images for lisp 1.5 plus the initial lisp library written in lisp. that includes bunches of test cases, the compiled compiler and other random crap. the listing does have some of my comments related to the conversion, but the original text is quite clear.
i was planning to bring it along when i go to stanford june 19-22, and would be willing to let someone scan it if desired. i’ve got other crap around in random piles, boxes, and “archives.”
I gave a 5-minute pitch at the conference for my LISP history project, but did not catch up with John. I tried to stay in touch with periodic emails, and ran into John and Ruth in person at John McCarthy’s 2012 Stanford memorial. But somehow we could never coordinate to scan his listing and other items from his “archives”.
Then in 2022 Ruth contacted me with the sad news that John had died in March of that year. Remembering our long correspondence regarding John’s LISP materials, she invited me to help her sort through John’s papers:
I have come across a PDP-1 notebook with a THOR manual (I think), some tapes containing I know not what, some copies of handwritten lecture notes (I think) of Dana Scott and Georg Kreisel. And I haven’t made it to the closet yet. I am throwing out a lot, and I may not have the right sensibilities to know what may be of interest.
I jumped at the chance, and spent an afternoon with her, bringing home several boxes of materials including the 1964 LISP 1.5 listing. Also she told me she’d discovered the copyright release for John’s famous book Anatomy of LISP and would be happy for an electronic edition to be posted online. That suggested an opportunity: ACM had included Anatomy in their 2006 Classic Bookscollection, but at that time the copyright status was not clear and an electronic edition could not be included, as was possible for many of the books in the collection. John wrote the book using Larry Tesler’s PUB document compiler, and many drafts were preserved in Bruce Baumgart’s SAILDART archive. John’s original plan was to adapt PUB’s output to a phototypesetter to achieve “book quality” output, but that did not work out so the book was published from pages printed on a Xerox XGP printer, at a low 192 dots/inch. Bruce Baumgart very generously did some work to recreate a bitmap-based PDF from SAILDART files, but it was still at 192 dpi and the content didn’t quite match the published version. So Ruth and I offered a clean, scanned PDF to ACM, and after verifying the rights they added this PDF to the website. [4]
The Computer History Museum accepted Ruth’s donation of the LISP 1.5 listing, some Stanford PDP-1 timesharing system documents (TVEDIT, RAID, and THOR), John’s Alvine LISP editor manual, John’s 1971-1972 lecture notes for the E123A course he taught at UCLA, three early MDL/MUDDLE documents, some ECL documents from Harvard, some early theorem proving reports (John implemented a theorem prover with David Luckham [5]), reports by Christopher Stratchey, Dana Scott, and Peter Wegner, an early 1979 version (by Harold Abelson and Robert Fano) of Structure and Interpretation of Computer Programs, and the four magnetic tapes Ruth had mentioned. (Al Kossow has promised to digitize the tapes; I suspect one contains John’s theorem prover; two may contain other LISP code.)
John Allen was a passionate computer scientist and educator. He held programming or research positions at Burroughs Sierra Madre, UC Santa Barbara, and GE Research (Goleta) in the early 1960s and at HP Labs and Signetics in the 1970s, as well as programming and research positions at Stanford from 1965 to about 1975, interspersed with teaching assignments at UCLA, UC Santa Cruz, and San Jose State. He also periodically taught part-time at Santa Clara University from 1984 to 2005. I wish I could have gotten to know him better.
[2] Ruth E. Davis and John R. Allen, co-organizers. Conference Record of the 1980 LISP Conference. Later reissued as: LFP ’80: Proceedings of the 1980 ACM conference on LISP and functional programming. https://dl.acm.org/doi/proceedings/10.1145/800087
[5] John Allen and David Luckham. An interactive theorem proving program. In Machine Intelligence 5, B. Meltzer and D. Michie, Eds., Edinburgh. U. Press, Edinburgh, 1970, pp. 321- 336.
P.S. After some study of the Georg Kreisel notes that Ruth mentioned, I believe they correspond to this item:
57. Kreisel, G. Intuitionistic Mathematics. Lecture delivered at Stanford University, 1962?, 270 pp. [Mimeographed].
The Archivists at Stanford’s Green Library agreed, and happily accepted a donation of the notes, which became Addenda 2024-122 to the Georg Kreisel papers (Collection SC0136): https://oac.cdlib.org/findaid/ark:/13030/kt4k403759/ .
In 2014, the Computer History Museum released the Xerox Alto file server archive, constituting about 15,000 files from the Xerox Alto personal computer including the Alto operating system; BCPL, Mesa, and (portions of the) Smalltalk programming environments; applications such as Bravo, Draw, and the Laurel email client; fonts and printing software (PARC had the first laser printers); and server software (including the IFS file server and the Grapevine distributed mail and name server). I told the story behind that archive here.
Today CHM released the Xerox PARC Interim File System (IFS) archive:
The archive contains nearly 150,000 unique files—around four gigabytes of information—and covers an astonishing landscape: programming languages; graphics; printing and typography; mathematics; networking; databases; file systems; electronic mail; servers; voice; artificial intelligence; hardware design; integrated circuit design tools and simulators; and additions to the Alto archive.
A blog post by David Brock introduces the archive. Access to the archive itself is available here.
I began working on this project in 2018 under an NDA with PARC: reading the old media prepared years earlier by Al Kossow, updating the conversion software I’d written for the earlier Alto project, and winnowing down a list of 300,000 files to the 150,000 files that I submitted to PARC management for approval. David Brock’s post ends with an Acknowledgments section noting all the people at CHM and PARC who contributed.
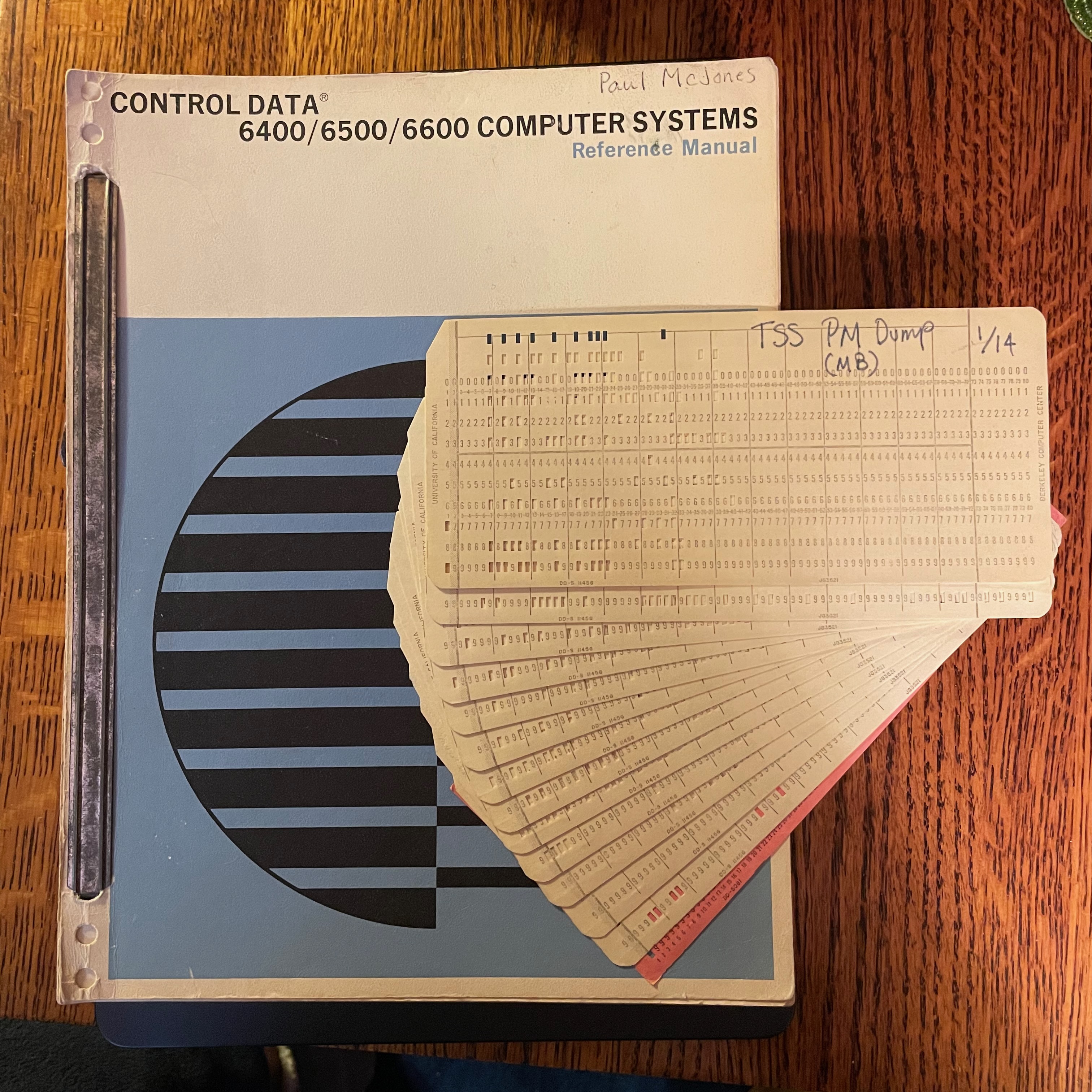
One of the artifacts preserved from the CAL Timesharing System project is a deck of 14 80-column binary cards labeled “TSS PM DUMP”. This is a program for a CDC 6000 series peripheral processor unit (PPU) to perform a post mortem dump to magnetic tape of the complete state of a (crashed) system: PPU memories, CPU memory, exchange package, and extended core storage. Another system utility program, TSS PP DUMP-TAPE SCANNER, allows selective display of portions of the dump to either the teletype or one of the system console displays. I believe Howard Sturgis wrote the PPU program and Keith Standiford wrote the CPU program.
I suspected this card deck was a version of a PPU program called DMP, for which a listing exists. Carl Claunch very generously offered to read (digitize) the cards. He produced a binary file tss.hex. I queried the ControlFreaks mailing list re a PPU disassembler, and Daiyu Hurst sent me a program ppdis.c that generates a listing with opcodes resolved and addresses, octal, and textual representations of each 12-bit word. After upgrading it to eliminate some K&R C function definitions and changing its input format to match tss.hex, I ran it, captured the output, and then began annotating it. As expected, it matched the DMP listing very closely, so I used those variable names, labels, and comments to update the output of ppdis.c, and added a few additional comments, including slight differences from the DMP listing.
The first card is a loader that loads subsequent cards up until one with a 6-7-8-9 punch in column one is encountered. The first card is loaded via the deadstart panel. Page 14 of the CAL TSS Operator’s Manual explains:
HOW TO MAKE A DIAGNOSTIC DUMP OF A SICK SYSTEM
Unfortunately, the dump program requires a different deadstart panel from the system dead start program. Reset the deadstart panel to
CAL TSS I, push the deadstart button, read the deck “TSS POST MORTEM” into the card reader, mount a tape on unit 0, and stand back and
watch it go. After the tape unloads, reset the deadstart panel to CAL TSS II and dead start the system as usual. Record the reel on which
the dump was made along with the other information relevant to the crash.
The Operator’s Manual also contains a set of CAL-TSS FAILURE LOG forms recording crashes and attempts to diagnose them.
The program on the cards is very similar to the DMP listing (which doesn’t include the loader card), with slightly different addresses and one or two small changes in the code.
The general structure of the program is to dump PPU 0 (whose memory is partially overlaid by the DMP program), then use this working space to dump PPUs 1-9, the exchange package (CPU registers), the CPU memory, extended core storage, and finally write a trailer record. The console display is used for operator messages: mounting a tape on drive zero, progress messages indicating which phase is taking place, and several error messages.
This doesn’t sound like a terribly difficult task, but it requires about 1000 instructions on the PPU, which has 12-bit words, one register, no multiply or divide, and an instruction time of 1 to 4 microseconds. There are some additional complications:
A PPU can’t access the memory of another PPU. When the overall system is deadstarted, PPU 0 begins running a 12-instruction program loaded from toggle switches on the deadstart panel, and the other PPUs are each suspended on an input instruction on a different I/O channel. Thus PPU 0 sends a short program to each one instructing it to output its own memory on a channel, which PPU 0 inputs and then outputs to the tape drive.
Similarly, a PPU can’t access extended core storage (ECS). So PPU 0 repeatedly writes a short program to the CPU memory that reads the next block from ECS to CPU memory, then does an “exchange jump” to cause the CPU to execute that program. The PPU then reads the block from CPU memory and writes it to tape.
In 2023 computers are all around us: our phones, tablets, laptops, and desktops, and lurking inside our television sets, appliances, automobiles, to say nothing of our workplaces and the internet. It wasn’t always that way: I was born in 1949, just as the first stored-program digital computers were going into operation. Those computers were big, filling a room, and difficult to use. Initially a user would sign up for a block of time to test and run a program that had been written and punched into paper tape or 80-column cards.cThe fact that an expensive computer sat idle while the user was thinking or mounting tapes seemed wasteful, so people designed batch operating systems that would run programs one after the other, with a trained operator mounting tapes just before they were needed. The users submitted their card decks and waited in their offices until their programs had run and the listings had been printed. While this was more efficient, there was a demand for computers that operated in “real time”, interacting with people and other equipment. MIT’s Whirlwind, TX-0, and TX-2 and Wes Clark’s LINC are examples.
The ability to interact directly with a computer via a terminal (especially when a display was available) was compelling, and computers were becoming much faster, which led to the idea of timesharing: making the computer divide its attention among a set of users, each with a terminal. Ideally the computer would have enough memory and speed so each user would get good service. Early timesharing projects included CTSS at MIT, DTSS at Dartmouth, and Project Genie at Berkeley. By 1966, Berkeley (that is, the University of California at Berkeley) decided to replace its IBM batch system with a larger computer that would provide interactive (time-shared) service as well as batch computing. None of the large commercial computers came with a timesharing system, so Berkeley decided they would build their own. The story of that project—from conception, through funding, design, implementation, (brief) usage, to termination—is told here:
Paul McJones and Dave Redell. History of the CAL Timesharing System. IEEE Annals of the History of Computing, Vol. 45, No. 3 (July-September 2023). IEEE Xplore (Open access)
How did I come to write that paper? In the winter of 1968-1969 I was invited to join the timesharing project. At that time I had about 2 years of programming experience gained in classes and on-the-job experience during high school and college (Berkeley). That wasn’t much, but it included one good-sized project—a Snobol4 implementation with Charles Simonyi—so the team welcomed me to the project. For the next three years I helped build the CAL Timesharing System, performed some maintenance on the Snobol4 system, and finished my bachelor’s degree. In December 1971, CAL TSS development was canceled, and I graduated and moved on to the CRMS APL project elsewhere on campus.
Those three years were hectic but immensely enjoyable. The team was small, with under a dozen people, housed first in an old apartment on Channing Way and then in the brand-new Evans Hall. Lifelong friendships were formed. People often worked into the night, when the computer was available, and then trooped over to a nearby hamburger joint for a late meal. Exciting things were going on around us. There were protests, the Vietnam War, and the first moon landings. Rock music seemed fresh and exciting. I had met my future wife in 1968, and we were married in 1970.
Rock posters in office on Channing WayMarching to the rallyNovember 1969: Antiwar Moratorium, in Golden Gate ParkView from brand-new Evans HallScenes from 1969-1971
As CAL TSS came to an end, we all agreed the experience could never be equalled. But we didn’t realize people in the future would be interested in studying our system, so we weren’t careful about preserving the magnetic tapes. However many of us kept manuals, design documents, and listings, plus a few tapes. In 1980 and again in 1991 we had reunions and I offered to store everything until it became clear what to do for the long run. Around 2003 I started scanning the materials and organizing a web site. In 2022 the Computer History Museum agreed to accept the physical artifacts, and this year they agreed to host the web site:
In April 2020, just as the Covid pandemic began, Annie Liu, a professor at Stony Brook University, emailed me to chat about programming language history. She suggested that Python, with its antecedents SETL, ABC, and C, would be a good topic for historical study and preservation. I mentioned that I’d considered SETL as an interesting topic back in the early 2000s, but unfortunately had not acted. After a few more rounds of email with her, I began looking around the web and Annie introduced me to several SETL people. Starting with these people, a few other personal contacts, and some persistence, I was soon in touch with much of the small but friendly SETL community, who very generously pored through their files and donated a wide variety of materials. The result is an historical archive of materials on the SETL programming language, including source code, documentation, and an extensive set of design notes that is available at the Software Preservation Group web site:
In addition, the digital artifacts and some of the physical artifacts are now part of the Computer History Museum’s permanent collection.
The SETL programming language was designed by Jack Schwartz at the Courant Institute of Mathematical Sciences at New York University. Schwartz was an accomplished mathematician who became interested in computer science during the 1960s. While working with John Cocke to learn and document a variety of compiler optimization algorithms, he got the idea of a high-level programming language able to describe such complex algorithms and data structures. [1] It occurred to him that set theory could be the basis for such a language since it was rich enough to serve as a foundation for all of mathematics. As his colleagues Martin Davis and Edward Schonberg described it in their biographical memoir to him: [2]
The central feature of the language is the use of sets and mappings over arbitrary domains, as well as the use of universally and existentially quantified expressions to describe predicates and iterations over composite structures. This set-theoretic core is embedded in a conventional imperative language with familiar control structures, subprograms, recursion, and global state in order to make the language widely accessible. Conservative for its time, it did not include higher-order functions. The final version of the language incorporated a backtracking mechanism (with success and fail primitives) as well as database operations. The popular scripting and general purpose programming language Python is understood to be a descendent of SETL, and its lineage is apparent in Python’s popularization of the use of mappings over arbitrary domains.
Schwartz viewed SETL first as a specification language allowing complex algorithms and data structures to be written down, conveyed to other humans, and executed as a part of algorithm development or even as a component of a complete prototype system. Actual production use would typically require reprogramming in terms of data structures closer to the machine such as arrays and lists. Schwartz believed that SETL programs could be optimized “by a combination of automatic and programmer-assisted procedures.” [3, page 70] He wrote several memos about his ideas for SETL [4, 5], and began assembling a project team — mostly graduate students. A series of design notes and memos called the SETL Newsletter was launched. [6] Malcolm Harrison, another NYU professor, had designed an extensible LISP-like language called BALM; in the first SETL Newsletter he sketched a simple prototype of SETL as a BALM extension. [7]
Over the following years the SETL Newsletters chronicled a long and confusing series of SETL implementations implemented with various versions of BALM and also with LITTLE, a low-level systems programming language.
BALMSETL (1971-1972) consisted of a runtime library of procedures corresponding to the various SETL operations, and a modification of BALM which replaced the standard BALM syntactic forms with calls to the appropriate procedures in the library. This runtime library used a hash-based representation of sets (earlier prototypes had used lists).
SETLB (spring 1972) consisted of a preprocessor (written in Fortran) that translated a simplified subset of SETL to BALMSETL. BALM was converted from producing interpretative code for a generalized BALM machine to producing CDC 6600 machine code.
SETLB.2 (1973?) was based upon a version of the BALM interpreter written in LITTLE, plus the SETL Run Time Library. It offered a limited capability for variation of the semantics of subroutine and function invocation by the SETLB programmer.
SETLA (1974?)’s input language was closer to SETL, but it still used the BALMSETL-based runtime library and BALM-based name scoping.
SETLC (1975?) consisted of a lexical scanner and syntactic analyzer (written in LITTLE), tree-walking routines (written in BALM) that built BALM parse trees), a translator that emitted LITTLE from the parse trees (written in BALM), and the LITTLE compiler. The generated LITTLE code used the SETL Run Time Library.
SETL/LITTLE (1977-1978?) consisted of a SETL-to-LITTLE translator, a runtime library, and a LITTLE-to-CDC 6600 machine code compiler (all written in LITTLE).
The final system (the only one for which source code is available) was ported to the IBM System/370, Amdahl UTS, DECsystem-10, and DEC VAX. There was also a sophisticated optimizer, itself written in SETL, which however was too large and slow to use in production. Work stopped around the end of 1984 as Schwartz’s focus moved to other fields such as parallel computing and robotics and many of the graduate students received their degrees. A follow-on SETL2 project produced more SETL Newsletters but no system.
Other SETL implementations
Starting in the mid 1970s, SETL-influenced languages were implemented at other institutions including Akademgorodok in Novosibirsk, and then at NYU itself. After a 30-year gestation period, GNU SETL was released in 2022. See https://www.softwarepreservation.org/projects/SETL/#Dialects for more.
Aftermath
Many reports and theses were written and papers were published. Perhaps the most well-known result was the NYUAda project, which was an “executable specification” for Ada that was the first validated Ada implementation. The project members went on to found AdaCore and GNAT Ada compiler.
[1] John Cocke and Jacob T. Schwartz. Programming Languages and Their Compilers. Preliminary Notes. 1968-1969; second revised version, Apri1 1970. Courant Institute of Mathematical Sciences, New York University. PDF at software preservation.org
[2] Martin Davis and Edmond Schonberg. Jacob Theodore Schwartz 1930-2009: A Biographical Memoir. National Academy of Science, 2011. PDF at nasonline.org
[3] Jacob T. Schwartz. On Programming: An Interim Report on the SETL Project. Installment 1: Generalities; Installment 2: The SETL Language, and Examples of Its Use. Computer Science Department, Courant Institute of Mathematical Sciences, New York University, 1973; revised June 1975. PDF at softwarepreservation.org
[4] Jacob T. Schwartz. Set theory as a language for program specification and programming. Courant Institute of Mathematical Sciences, September 1970, 97 pages.
[5] Jacob T. Schwartz. Abstract algorithms and a set theoretic language for their expression. Computer Science Department, Courant Institute of Mathematical Sciences, New York University. Preliminary draft, first part. 1970-1971, 16+289 pages. PDF at softwarepreservation.org
Maarten van Emden died on January 4, 2023, at the age of 85.[1] He was a pioneer of logic programming, a field he explored for much of his career. I was not in his field, and only got to know him starting in 2010, so this is a personal, but not professional, remembrance of a very dear friend.
Maarten van Emden, 26 February 2011
His life
Maarten was born in Velp, the Netherlands, but his family soon moved to the Dutch East Indies, where his botanist father was working on improving tea plants. In 1942 the Japanese invaded. Maarten’s father escaped to join the resistance, but Maarten, his younger sister, and his mother were sent to a detention camp. As the war came to a close, his father was able to rescue and reunite the family. Over the next few years they returned to the Netherlands, with a brief return to the newly-formed Indonesia, followed by boarding school in Australia for Maarten. They were finally reunited in the Netherlands in 1954, where Maarten began his final year of high school. After graduating in 1955, he went to national flight school (Rijksluchtvaartschool). He did a year of military service, including flight training, and then joined KLM Royal Dutch Airlines. But KLM was adopting DC-8 jets for transatlantic service, whose speed, capacity, and ease of operation led to the need for fewer pilots. Maarten took advantage of a company program to enroll part-time in an engineering curriculum at the University of Delft. Later he was laid off by KLM and finished a master’s degree as a full-time student. He then enrolled in the PhD program administered by the University of Amsterdam with research at the Mathematisch Centrum (now CWI), and also made several visits to the University of Edinburgh. His 1971 dissertation was An Analysis of Complexity and his advisor was Adriaan van Wijngaarden. Maarten was awarded a post-doctoral fellowship by IBM, which he spent at the Thomas J. Watson Research Center in Yorktown Heights, NY during the 1971-1972 academic year, before returning to Edinburgh for a research position under Donald Michie in the Department of Machine Intelligence. In 1975 he accepted a professorship at the University of Waterloo, and in 1987 he moved to the University of Victoria.
Programming
Maarten was one of 15 individuals recognized as Founders of Logic Programming by the Association for Logic Programming.[2] His work began with an early collaboration with Bob Kowalski[3] and continued throughout his career with collaborations and individual projects to explore many aspects of the field. Underlying his interest in logic programming was a fascination with programming and programming languages of all sorts.[4] His first language was Algol 60, which he taught himself using McCracken’s new book[5] when his university suddenly switched from Marchant calculators to a Telefunken TR-4 computer for the numerical methods course.[6] Moving on to the MC he was surrounded by ALGOL experts (his advisor van Wijngaarden was a member of the ALGOL 60 Committee and the instigator of the infamous ALGOL 68). Maarten was originally attracted to Edinburgh after hearing about the POP-2 timesharing system of Burstall and Popplestone; it was only later that he realized he’d initially used POP-2 as if it was ALGOL rather than a rich functional programming language. During his post-doc at IBM he learned APL and Lisp. Fred Blair was implementing a statically-scoped Lisp for the SCRATCHPAD computer algebra group.[7] And William Burge, who had worked with Burstall and Landin, was spreading the gospel of functional programming.[8] Ensconced in Edinburgh in 1972, he became an early convert to Kowalski’s logic programming, which he noted could be traced back as early as Cordell Green’s paper at the 4th Machine Intelligence workshop.[9] But Maarten’s first impression of Preliminary Prolog was not positive — the frequent control annotations seemed to detract from the logic. Nevertheless, he and Kowalksi began writing short programs to explore the ideas. And when David Warren returned from a visit to Marseille with a box of cards containing Final Prolog as well as his short but powerful WARPLAN program, things changed. The language no longer needed the control annotations, and Warren quickly ported its Fortran-coded lowest layer to the local DEC-10. WARPLAN served as a tutorial for all sorts of programs in the new language. Maarten was surprised that his friend Alan Robinson, the inventor of resolution logic, wouldn’t give up Lisp for logic programming.[10] At Waterloo, he advised Grant Roberts, who built Waterloo Prolog for the IBM System /370, and another series of students who built several Prologs for Unix. At Victoria, he wrote a first-year textbook for science and engineering students based on C:
It is indeed true that object-oriented programming represents a great advance. It is also true that polymorphism in object-oriented programming does away with many if-statements and switch statements; that iterators replace or simplify many loops. But experience has shown that introducing objects first does not lead to a first course that produces better programmers; on the contrary. It is as much necessary as in the old days to make sure that students master variables, functions, branches, loops, arrays, and structures.
I had the good fortune to grow up in three distinctive programming cultures: the Mathematical Centre in Amsterdam, the Lisp group in the IBM T.J. Watson Research Center, and the Department of Machine Intelligence in the University of Edinburgh. Though all of these entities have ceased to exist, I trust I am not the only surviving beneficiary.
If this book is better than others, it is due to my choice of those who were, often without knowing it, my teachers: H. Abelson, J. Bentley, W. Burge, R. Burstall, M. Cheng, A. Colmerauer, T. Dekker, E. Dijkstra, D. Gries, C. Hoare, D. Hoffman, N. Horspool, B. Kernighan, D. Knuth, R. O’Keefe, P. Plauger, R. Popplestone, F. Roberts, G. Sussman, A. van Wijngaarden, N. Wirth.
As different as we were, Maarten and I had a few things in common: fathers who piloted B-24 bombers in WWII, a charismatic mutual friend named Jim Gray, attendance at the 1973 NATO Summer School on Structured Programming, books named Elements of Programming, and a fascination with the early development of programming languages. Jim Gray had been an informal mentor for me at UC Berkeley as I worked on CAL Snobol and Cal TSS. Then he left Berkeley for IBM Research in Yorktown, and made friends with Maarten. Jim soon decided he couldn’t tolerate life on the east coast, but before leaving he encouraged Maarten and his wife Jos to drive across the country and visit him in California, where he would show them around. They took him up on the offer, and during a brief stay in fall 1972 at Jim’s home in Berkeley I met Maarten, but didn’t make much of an impression on him (although he later told me Jim had mentioned the “great programmers on Cal TSS”). The next summer both Maarten and I attended the NATO Summer School on Structured Programming at Marktoberdorf, but neither of us remembered encountering the other. Maarten mentioned the summer school in his remembrance of Dijkstra.[12]
In 1974 I caught up with Jim Gray again, joining IBM Research in San Jose (before Almaden). The next summer Maarten visited Jim, although I didn’t learn of it until much later:
“After I returned to Europe Jim and I kept writing letters. In the summer of 1975 I was in a workshop in Santa Cruz and Jim came up in a beautiful old Porsche. I was at the height of my logic programming infatuation. Jim was rather dismissive of it. Nothing of what he told me about System R turned me on; the relationship died with that meeting. How I wish I could talk to him now about the mathematics of RDBs, which I started working on recently.”
[Maarten van Emden, personal communication, September 3, 2010]
Maarten left three technical reports with Jim, who passed them along to me.[13][14][15] I looked at them, and then put them aside for the next 35 years. In the fall of 2010 I had retired and was spending more time on software history projects. I’d been following Maarten’s blog; a recent pair of articles about the Fifth Generation Computer System project and the languages Prolog and Lisp[16][17] prompted me to contact him about a project I was contemplating: an historical archive of implementations of Prolog.[18] That began a friendship carried out mostly through some 2000 emails and almost 400 weekly video calls, plus one in-person visit when Maarten visited the Bay Area in early 2011. I will always remember his charming manners, gentle humor, wide-ranging interests, and intriguing stories.
Acknowledgments
Thanks to Maarten’s daughter Eva van Emden for information about his life.
50 years ago Alain Colmerauer and his colleagues were working on Prolog 0:
“A draconian decision was made: at the cost of incompleteness, we chose linear resolution with unification only between the heads of clauses. Without knowing it, we had discovered the strategy that is complete when only Horn clauses are used.”
Now the friends of Alain Colmerauer are calling for 2022 to be “The Year of Prolog”. They’re marking the 50th anniversary with:
An Alain COLMERAUER Prize awarded by an international jury for the most significant achievement in Prolog technology.
A “Prolog School Bus” that will travel to reintroduce declarative programming concepts to the younger generation. This is a long-term initiative that will be initiated during the year. The purpose of this “Tour de France” (and elsewhere) will be to familiarize schoolchildren with Prolog, as they are already familiar with the Scratch language. At the end of this school caravan, a prize will be awarded to the ‘nicest’ Prolog program written by a student.
Alain Colmerauer – photo from his web site http://alain.colmerauer.free.fr
It’s called An idea crazy enough…..Artificial Intelligence and it’s being developed by Colmerauer‘s friends at Prolog Heritage via a crowd-funded project at Ulele.
Colmerauer died 12 May 2017; the hoped-for tribute this fall has evolved:
The project is a film to portray Alain Colmerauer’s life and work – his contribution to Logic Programming and Constraints Logic Programming – all brought to life through interviews with some of the key participants of his time, complemented by images and documents from the archives. In fact that was the best solution to invite witnesses in this period of sanitary difficulties.
A 20 Euro contribution gets you an invitation to an exclusive preview of the film online; a 50 Euro contribution gets you the invitation, your name in the credits as a donor, and a digital version of the documentary.
On May 22 and 23, 2017, the Computer History Museum held a two-day meeting with more than 15 pioneering participants involved in the creation of the desktop publishing industry. There were a series of moderated group sessions and one-on-one oral histories of some of the participants, all of which were video recorded and transcribed.
Building on this meeting, three special issues of the IEEE Annals of the History of Computing were published, telling the stories of people, technologies, companies, and industries — far too much for me to cover here, so I will provide these links:
Web extras: Dave Walden’s page of corrections, links to the original video recordings and transcriptions, and legend for the group photograph heading this post.
Last but not least, I had the pleasure of interviewing Liz Bond Crews, who worked first at Xerox and then Adobe to forge relationships and understanding between the purveyors of new technology (laser printers and PostScript) and the type designers, typographers, and designers who adopted that technology. An edited version of that interview appears in the third special issue of Annals:
Logic programming has a long and interesting history with a rich literature comprising newsletters, journals, monographs, and workshop and conference proceedings. Much of that literature is accessible online, at least to people with the appropriate subscriptions. And there are a number of logic programming systems being actively developed, many of which are released as open source software.
Unfortunately, the early years of logic programming are not as consistently preserved. For example, according to dblp.org, the proceedings of the first two International Logic Programming Conferences are not available online, and according to worldcat.org, the closest library copies of the two are 1236 km. and 8850 km. away from my home in Silicon Valley. Early workshop proceedings and many technical reports are similarly hard to find (but see [1, 2]!). And the source code of the early systems, although at one time freely distributed from university to university, is now even more difficult to find.
As noted by people like Donald Knuth [3], Len Shustek [4], and Roberto Di Cosmo [5], software is a form of literature, and deserves to be preserved and studied in its original form: source code. Publications can provide overviews and algorithms, but ultimately the details are in the source code. About a year ago I began a project to collect and preserve primary and secondary source materials (including specifications, source code, manuals, and papers discussing design and implementation) from the history of logic programming, beginning with Marseille Prolog. This article is intended to bring awareness of the project to a larger circle than the few dozen people I’ve contacted so far. A web site with the materials I’ve found is available [6]. I would appreciate suggestions for additional material [7], especially for the early years (say up through the mid 1980s). The web site is hosted by the Computer History Museum [8], which welcomes donations of historic physical and digital artifacts. It’s also worth noting the Software Heritage Acquisition Process [9], a process designed by Software Heritage [5] in collaboration with the University of Pisa to curate and archive historic software source code.
Maarten van Emden provided the initial artifacts and introductions enabling me to begin this project. Luís Moniz Pereira provided enthusiastic support, scanned literature from the early 1980s [1, 2], and encouraged me to write this article. And a number of other people have generously contributed time and artifacts; they are listed in the Acknowledgements section of [6] as well as in individual entries of that web site.
References
Luís Moniz Pereira, editor. Logic Programming Newsletter, Universidade Nova de Lisboa, Departamento de Informática. Issues #1-#5, 1981-1984. [Note that this newsletter was typeset, galley-proofed, and printed in color.] http://www.softwarepreservation.org/projects/prolog/lisbon/lpn/
Do you have a card deck or listing of the original Marseille interpreter? Or the source code for NIM IGÜSZI PROLOG, IC-Prolog, EMAS Prolog, or LogLisp, just to name a few?
Elements of Programming by Alexander Stepanov and Paul McJones
After almost 10 years in print, Addison-Wesley elected to stop reprinting Elements of Programming and has returned the rights to us. We are releasing an “Authors’ Edition” in two versions:
A few months after my article “The LISP 2 Project” was published, I learned from Paul Kimpel that the language GTL includes a “non-standard” version of LISP 2. GTL stands for Georgia Tech Language. It is an extension of the Burroughs B 5500 Algol language, and its implementation extends the Burroughs Algol compiler. There is a new data type, SYMBOL, whose value can be an atomic symbol, a number, or a dotted pair. There is a garbage collector, and a way to save and restore memory using the file system. GTL was designed by Martin Alexander at the Georgia Institute of Technology between 1968 and 1969. The source code is available as part of the Burroughs CUBE library, version 13, and the manual is available via bitsavers.org; see here for details.
















{kind=link}